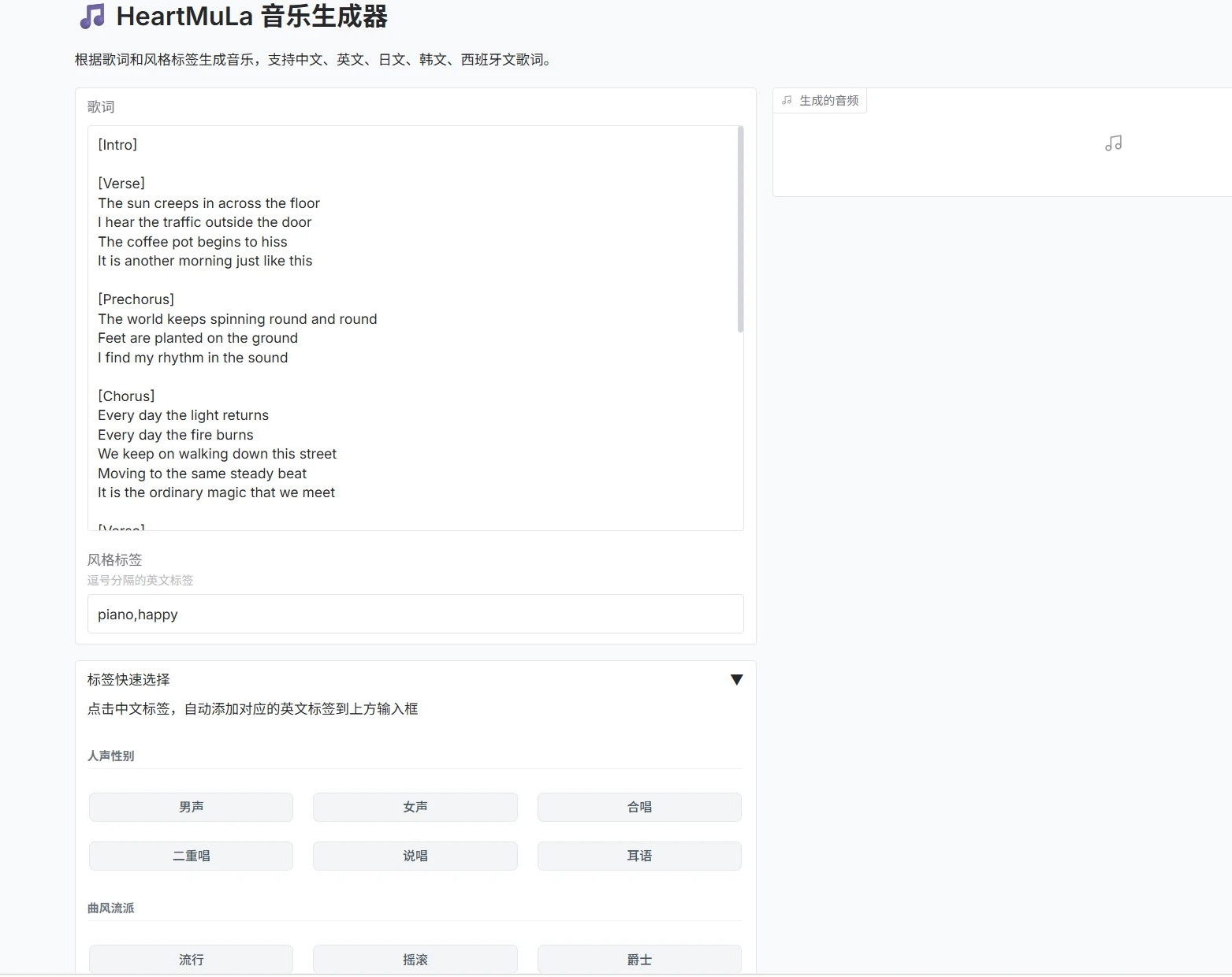
AI模型简介:
HeartMuLa是一款AI音乐自动创作软件。
HeartMuLa 框架由四大核心组件构成,每个组件都针对特定的音乐处理任务进行了深度优化:
1. HeartMuLa(主生成模型)
架构特点:采用创新的双层级整体-部分架构,能够同时处理全局音乐结构和局部细节
生成能力:基于歌词和风格标签生成专业级音乐,支持细粒度控制不同歌曲段落(前奏、主歌、副歌、桥段等)的风格
多语言支持:原生支持英语、中文、日语、韩语、西班牙语等多种语言的歌词理解和生成
2. HeartCodec(音频编解码器)
技术规格:12.5Hz采样率的高效编解码器,在保持高重建保真度的同时,能够捕捉长距离音乐结构
核心优势:在保留精细声学细节的同时,大幅降低计算复杂度,为实时音乐生成提供基础
3. HeartTranscriptor(歌词识别模型)
架构基础:基于Whisper架构专门优化,针对真实世界音乐场景的歌词识别进行了调优机器学习与人工智能
应用场景:能够准确识别复杂背景音乐中的歌词内容,为音乐理解和版权管理提供支持
4. HeartCLAP(跨模态对齐模型)
功能定位:音频-文本对齐模型,为音乐描述建立统一的嵌入空间
核心能力:支持跨模态检索,实现音乐与文本描述的精准匹配,为个性化推荐和内容发现提供基础
软件特点:
训练规模与数据
HeartMuLa 模型在超过100,000小时的海量音乐数据集上进行预训练,这种规模的训练使模型能够学习长程时间依赖和全局 音乐结构。通过大规模数据训练,模型获得了对音乐语法、和声进行、节奏模式的深度理解。
性能对比
内部测试表明,HeartMuLa-7B版本在音乐性、音质保真度和生成可控性方面达到了与商业级系统Suno相当的性能水平。这一成就标志着 开源音乐AI领域的重要突破,为非商业研究提供了强大的基础模型。
专用场景优化
HeartMuLa 特别适合短视频背景音乐等短时音乐生成场景,能够在30-240秒的时间范围内生成结构完整、风格一致的音乐作品。其生成的音乐具有专业录音室级别的音质,满足现代数字内容创作的需求。音乐创作与理论
应用场景与创新价值
内容创作赋能
HeartMuLa 为内容创作者提供了强大的工具,能够将简单的歌词和风格描述转化为完整的音乐作品。无论是独立音乐人、视频创作者还是游戏开发者,都能从中受益,大幅降低 音乐创作的技术门槛。
学术研究价值
作为开源项目,HeartMuLa 为音乐信息检索、音频生成、跨模态学习等领域的学术研究提供了宝贵的基准模型和实验平台。其模块化设计允许研究者针对特定组件进行改进和创新。
多模态融合
HeartMuLa 的跨模态能力使其能够与其他AI系统(如视频生成模型)无缝集成,推动多模态内容创作的发展。例如,可以结合视频理解模型,为特定场景自动生成匹配的背景音乐。
许可证与伦理考量
HeartMuLa 项目采用严格的非商业许可策略,源代码、模型和文档均在GitHub上公开,但仅限非商业研究和教育用途。项目团队明确禁止任何商业使用,强调AI音乐技术应该以负责任的方式发展,尊重创作者权益。开放源代码
未来发展路线
项目团队正在积极开发多个重要功能:
推理优化:实现推理加速和流式推理,提升生成效率
参考音频条件生成:允许用户提供参考音频来指导生成过程
细粒度控制:增强对 音乐元素(和声、节奏、配器)的精细控制能力
模型扩展:计划发布更大规模的HeartMuLa-oss-7B版本,进一步提升生成质量
总结:
HeartMuLa 代表了 开源音乐AI社区的重大进步,通过开放基础模型和工具链,为全球研究者和创作者构建了一个共享的创新平台。其技术架构和设计理念为未来的音乐基础模型发展提供了重要的参考范式,有望推动整个音乐AI领域的技术演进和应用创新。
本地整合包配置说明:
1、英伟达16G+24G内存就可以愉快玩耍了。模型是3b应用程序商店
2、汉化了界面
3、人气高就继续开发
更新说明:
v 20260507
1、更新模型为最新的官方模型
2、添加大量控制标签
3、修正部分bug
4、对界面重新修改了下,更加简洁






最新评论
flyme auto版
你这个是便携版,无法自动下载模型。
闪豆现在限制下载数量,电脑已经被限制了
已更新
请更新7.2.3.32
那就应该是失效了,等下一次更新或者更换其它软件
不能用~提示升级~升不了提示安装失败~VIP的歌不能听直接切歌
已经无法直接登录